
前端越管越宽,腾讯Now直播如何把监控体系做到极致?
来源:安防百科 /
时间: 2024-05-21

作者 | 何方舟
编辑 | 张笑菊
NOW 直播成立三年以来,前端团队涵盖的业务范围越来越广阔。从最初的 Hybrid App,到 React Native 再到如今的小程序,单维度的监控手段已经不足以帮助开发人员及时发现与定位问题。IVWEB 团队在不断的业务实践中,沉淀出了一套比较完善的监控方案。
在 GMTC 全球大前端技术大会(深圳站)2019 上,腾讯高级 Web 前端工程师何方舟以产品遇到的实际问题挑战为背景,详细讲解了实现大前端监控的一些解决方案。本文即根据何方舟的演讲整理而成。以下为正文。
本次分享将会从三个方面来介绍,首先是 NOW 直播在大前端时代的业务演进,以及我们前端的发展路程;其次是我们在做前端监控的实践中遇到的一些问题;最后是我们在实践中沉淀出的一套前端监控方案 Aegis 的系统架构。
NOW 直播的业务形态演进
我简单列了下直播的发展过程,早在零几年的时候,中国的直播已经开始出现,但当时主要是以秀场直播为主。
在 2014 年的时候,国内就以虎牙、斗鱼这一类的游戏直播为代表,突然有了一个爆发式的增长。如果大家平常玩游戏的话,这些应该都是可以关注到的。
到了 2016 年,所谓的直播元年——千播大战。这个时候是泛娱乐化,人人都可以成为主播,涌现出了一大批直播平台。其中比较有代表性的,应该就是映客、花椒还有我们的 NOW 直播。
1.NOW 直播前端发展历程
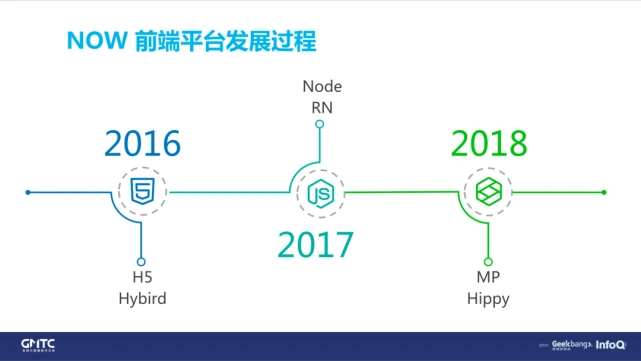
这里我简单的列了一下,NOW 直播前端职责的发展过程。
(1)在 2016 年,NOW 直播刚起步,当时我们所负责的主要是传统 H5,还有独立版 App 里面的 Hybird 的页面。当时我们要解决的一个首要问题,就是怎么把前端框架先跑起来。
(2)到了 2017 年,因为各种业务功能都比较稳定了,这时候我们开始对本身原有的一些框架进行反思,也包括去扩展更多边界。比较突出的是,一个是引入了 Node,一个是引入了 RN。主要做了两个事情:
把接入层方面的工作,移交到 Node 上面来进行执行。借助 Node SSR 的能力,帮助页面更好地提升性能体验。
RN 也是当时的一个全新的尝试,我们把客户端首页的 90% 的首屏的页面,都全部动态化,一方面是提升性能;另外一方面,让产品可以快速更新。
(3)2018 年,对业务来说,需要更大的增长,就是说我们需要有更多的平台给 NOW 直播引流,所以我们尝试在别的平台上面加入我们的直播。对应到前端上来看,也就是在这一年,我们做了 NOW 直播的一个小程序。比如在浏览器、腾讯看点,还有腾讯微视里面也加入了我们的直播。为了它的性能体验,我们接入了对方应用类的一些动态化框架,比如 Hippy ,还有 Vue。
可以看到,我们整个前端的发展其实是和业务方息息相关的。脱离了业务的技术,其实是没有意义的。
2. 监控体系

做监控就是为了帮助我们发现业务中存在的问题。从整体来说,早在 2016 年的时候,我们就已经沉淀出一套比较好的监控体系了,这得益于腾讯内部已经有很多好的监控平台。总的来看,我们会把监控分为两端,一个是 C 端,一个是 Node 端(服务端)。
C 端包含了前面提到的 H5 Hybrid,还有一些跨平台的小程序、RN 这一类,C 端的监控分为以下 4 个模块:
(1) 异常收集,我们使用的是以前团队开源的一套——BadJS,其实是在 2015 年做的一套纯前端架构的一个方案。BadJS 除了承载错误收集这一能力以外,还承担了日志上报能力。
(2) 性能监控,我们用了腾讯内部现有的几个平台,罗盘报表和伯努利的报表,可以看到每天资源加载成功失败的情况。
(3) 智能告警则是用了内部云监控的一个平台,可以做到按比例以及按累积量触发告警。
(4) 日志上报可以结合客户端的日志帮助定位问题。
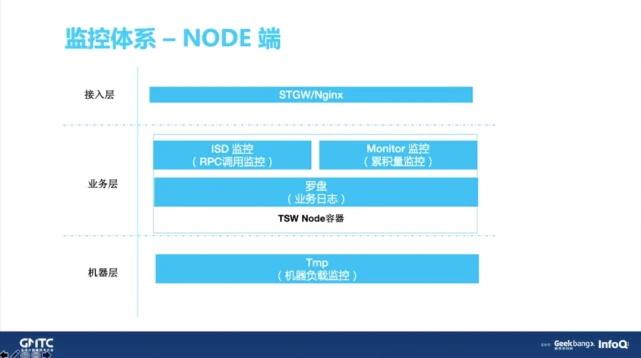
接下来看一下 Node 端上报的架构(如上图所示),它本质上还是归属于服务端这一类。整体来说,腾讯在服务端的上报沉淀是比较深的,现有的架构体系我们可以直接拿来用:
(1) 由 STGW 作为腾讯所有业务的接入层,它会监控业务返回的状态码以及一些长度。
(2) 这里用的是 TSW 做一个业务容器,TSW 也是腾讯开源的一个 Node 容器架构,它可以做到 RPC 服务的测速,还有成功失败率的调用,以及实时日志的云端上面的抓包。
(3) 机器运维层,这个用的是 Tmp 监控,可以看到一个机器整体的 CPU 内存,还有吞吐量负载。

整体来说,我们已经有一套比较完善的监控体系了,但仍然存在一些问题(如上图)。
2018 年,我们接手另外一个团队交接的全新项目时,发现它整体监控各方面都比较匮乏。我们就尝试把之前的那一套监控体系移接过来,接入过程中发现了几个比较大的问题:
(1) 以前的监控系统实际上是比较复杂的,对于一个刚来的同学来说,做一个完整的前端上报,需要去了解 10 个系统。也就是说如果真的遇到了线上的问题,需要去 10 个系统中去查,这对开发人员来说是极其不友好的。
(2) 以 CGI 测速举例,需要在刚才提到的 Monitor 平台上面,每当一个新 CGI 接进来,都需要去申请三个测速点。刚开始做一个新页面还比较好,每次申请一下。但是当几百个 CGI 过来,需要一口气申请几百个测速点,然后再一个个加到代码里面去,再做打点上报。所以说它对开发侵入性非常强。
(3) 接手项目之后,老板反馈说这个体验很差,需要优化。我们就开始先打点,以前是一个非 SSR 的方案,然后优化之后,加入了 SSR 技术。但是我们改完这个之后,对应的手动打点的位置,并没有去做修改。结果导致做完优化上线之后,老板一看数据一点提升都没有。当我们做了一些技术方案变动的时候,还要进行一些手动的操作,这个是非常繁琐的。
(4) 监控平台使用体验差,因为这些监控平台本身不是为前端做的。腾讯有很多监控平台,原本只是为后端做测速的质量上报用,当拿到前端来使用时,并没有为前端做一些定制化的东西。所以导致前端在使用这些监控平台时,体验非常差。
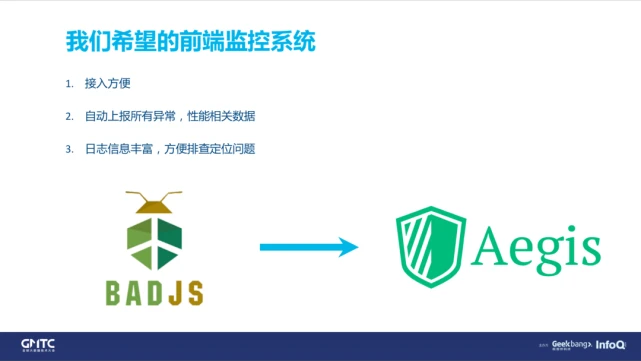
这个时候,我们也开始思考,是不是要自己做一个全新的平台?当时我们也调研了一下业界非常优秀的一些框架。但是对于腾讯来说,监控数据是比较敏感的,所以我们还是要尽量选用自己的监控方案。
虽然腾讯内部有很多监控系统,但是没有一个是一站式监控前端所有资源的监控系统。于是我们重新做了一个监控方案,我们希望的前端监控方案有以下特点:
(1)接入简单,import 一个包进来,马上就可以用了。这对开发人员来说应该是最简单的,也是我们期望的。
(2)当发现问题的时候,可以快速定位到。自动上报所有应用数据,无需关注开发。
(3)为用户提供可靠的智能告警功能,不放过每一个错误。
所以,我们在 BADJS 的基础上,提出了 Aegis 这一套全新的监控方案。
前端监控实践
我们对BADJS进行二次开发,于是有了Aegis这样一套监控平台。接下来就看一下Aegis监控平台到底是怎么做的,以及在做Aegis上报里面遇到的一些实际问题。
1. 无侵入上报

首先要解决的就是,如何帮助开发人员真正的减少手动打点的开发量?这块相关的资料比较多,我简单说一下。
整体的监控,我们需要采集的数据分为 4 类,即:
JS的异常错误;
资源测速;
接口的成功率、失败率;
性能。
其实浏览器已经提供了比较好的 API;当然对于不好支持的部分,我们可以采用 Patch 方式,对一些原生方法进行处理,从而做到无侵入开发上报的方式。
如上图,大家可以看到 JS 错误监控里面有个 window.onEerror ,但在资源测速监控里面又用了 window.addEventLisenter('error') ,其实两者并不能互相代替。
window.onError 是一个标准的错误捕获接口,它可以拿到对应的这种 JS 错误;windows.addEventLisenter('error')也可以捕获到错误,但是它拿到的 JS 报错堆栈往往是不完整的。同时 window.onError 无法获取到资源加载失败的一个情况,必须使用 window.addEventLisenter('error')来捕获资源加载失败的情况。
2. 上报端框架

接下来看一下整体的上报端 SDK 的框架。总的来说,把一个页面的数据上报上去?很简单,第 1 步收集,第 2 步处理,第 3 步上报。
这里主要讲一下,我们为什么要在前端前置的做一些数据处理?主要有几个原因,首先,我们需要对数据做一些清洗,举个例子,假设有单一的一个用户,可能他触发了一个循环不停的报错,那么上报上来的数据其实是无意义的,而且还会浪费他上报的带宽,所以这里我们要对这种错误上报进行限频。
其次,因为浏览器差异,各个浏览器它捕获到的 JS Error 的对象是会有差异的,所以我们要在这里对 JS Error,把它们统一格式化再进行上报。
3. 上报端流程
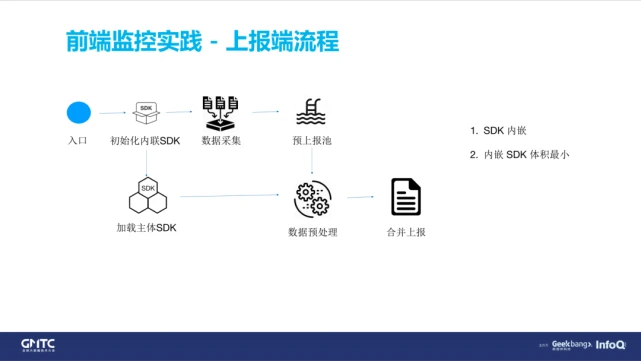
然后我们来看一下整体的上报流程(如上图)。
我们先会在页面上内嵌一个最小的 SDK,并且一定是要放在头部的。如果把 SDK 全部异步加载,那么 SDK 必然无法采集到加载之前的一些数据。这里我们采用了一个折中的办法,只把最小的采集端缩小成一个最简版的 SDK 放在头部,然后再进一步的去加载主体的 SDK, 采集端采集到的数据,会先放入到一个内存的池子里面,然后等到主体端的 SDK 加载完成之后,再从池子里面把数据读取出来,然后上报。
那么问题来了,如果主体 SDK 加载失败了怎么办?
我们的做法是再加入一层保护机制,首先加载主体 SDK 会有两次重试的机制。如果再次失败,会先把上报池中要上报的数据先存在 IndexedDB 里面,作为本地日志。等到用户下一次进入页面的时候,再把本地日志历史中的这些日志一并进行上报;或者服务器直接下发上传指令,主动上传日志。
4. 日志上报
(1)上报请求中的一些问题

上报一般都是用 new Image 来发送,因为我们会对上报的请求做一个合并,请求长度太大会导致请求失败。比如说,三秒内的多条请求,会合并成一条请求发出去,但是合并之后就会导致一个问题,发出的长度如果超过了 2KB,也就是一个 get 请求的最大长度,那么这条请求是会失败的。
最直接的解决办法是用 xhr 走 post 请求的方式来发送。但是又会面临另外一个问题:用 XHR 发送的话,这个请求的优先级会升级为最高,将影响到业务主体的消息请求。
这个时候我们又看到一个新的 API,就是 sendBeacon,那么用这个是不是问题就得到解决了呢?我们尝试用了 sendBeacon,同样也发现了问题,它的优先级也是要区分的。
如果 sendBeacon 没有带 FormData 的话,它的优先级是比较低的,不会影响业务。如果用的是 FormData 的形式,它的优先级依然是比较高的,这也是我们之前遇到的问题,这一点在官方文档中并没有提到。当时我们在本地测试之后,就上线了使用 sendBeacon 的版本,发布之后很快就出现测速告警,图片延迟率变得特别高,多了三秒之多。我们针对这个问题定位了很久,最后发现是因为 sendBeacon 的这一改动。
兜兜转转,好像只能回到 new Image 的解法,我们再次使用了它,并给它加了一层保护,首先压缩合并并判断它压缩后的请求,之后再对过长的压缩进行拆分,保证它在可用的长度范围内进行压缩。
压缩之后用 new Image 发送的话,由于压缩的计算耗时,终究会影响到业务的体验。所以我们就借助了requestIdleCallback这个方法。这个 API 做了什么事情呢?它可以检测到浏览器的资源空闲状态。可以在空闲时发送业务请求。
本来以为这样就可以了,后来产品同学又来找我们反馈,说上报数据老是有丢失,还有用户页面停留时间过长,以及数据量各种不对。我们试验之后得出的结果是,一个浏览器关闭了之后,那些没有发送的请求其实是会丢掉的。一般的做法就是在 Windows 里面发一个同步的 XHR 请求,但是在移动端其实是没有效果的。遗憾的是,即使我们用 sendBeacon,页面关闭后仍然不会去发送请求,好像陷入了死局,最终我们的解决方案是借助终端的能力去发送关闭这种事件的一些请求。
(2)打通前后端日志
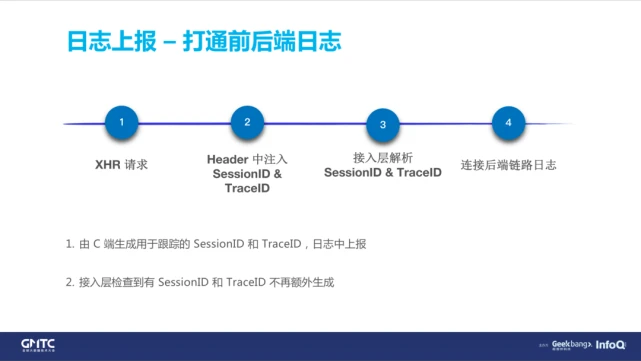
大家都知道,后端是有一套全链路日志监控的,那么前端如何接入这种全链路日志呢?
传统的全链路日志,起始点都是在后端的接入层。对于前端来说,假如某一个 CGI 真的出错了,怎么和后端的请求关联起来呢?在之前这是没办法解决的,所以我们提出来把全链路日志的起始点提前到 C 端,直接在 C 端生成 Session ID 和 TraceID,加入头部直接带入给后端,后端检测到我们的请求有 Session ID 和 TraceID 的时候,帮我们多生成一个 span 去做全链路监控。
需要注意的是,这里是在 XHR 头部里面加了 Session ID 和 TraceID 的,它不是一个标准的 Header,它会让服务器把这里错认成一个复杂请求。其实同域不会发,如果是非同域的状况下,它会去发一个 option 的请求,询问服务器是不是会支持该 Header,这就会造成业务上面的额外开销。所以现在的全链路日志,我们只在同域的接口下面才会去启用它。
5.异常监控
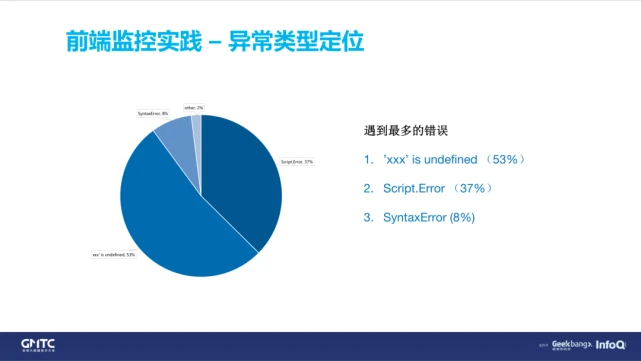
如上图所示,我们收集了一下 2018 年遇到的最多的错误的三种情况。第 1 个是‘xxx’ is undefined;第 2 个是 Script.Error;第 3 个是语法错误。

造成‘xxx’ is undefined 的主要原因有两种:
第 1,其实大家自己写代码的时候,现在各种 Lint 工具都可以帮我们规避掉‘xxx’ is undefined 这类问题,但为什么还是会出现呢?常见的一个情况就是后台接口返回的数据是 JSON 格式,加上某个后端服务一旦出现了问题,导致返回的数据异常。这是遇到的最多的一个情况。
第 2,大家现在的应用里面应该都有分包的工作,一般都会把一些主体的包单独拆出来,一旦这种包加载失败,就会出现 ‘xxx’ is undefined 。
给大家看一个我们实际遇到的案例。
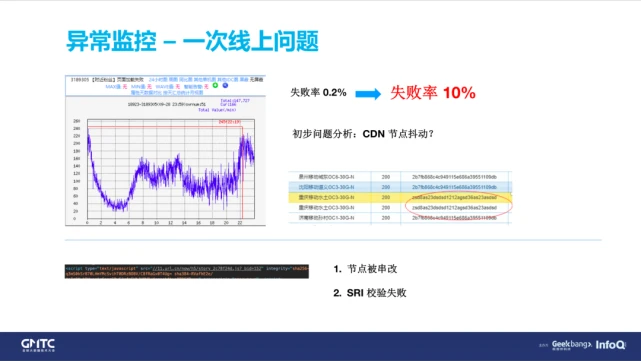
为什么会存在 CDN 被劫持的情况呢?
大家知道 CDN 实际上是主栈要推到各个 CDN 栈上去的。虽然在我们的页面上面是走 HTTPS,但是从主栈把资源推到各个 CDN 上的时候,为了追求速度是不会去走 HTTPS 的,而是走 HTTP。其实这就给了一些运营商可趁之机,在这个阶段就把 CDN 上的资源做了一个篡改,导致资源上了 HTTPS 还是被劫持。
当然,我们肯定知道会存在这种劫持情况。所以很早就加了一个 SRI 的方案,做防劫持的处理。简单讲一下,比如 SRI 会在 Script 标签上面有一个指纹,当你通过构建工具生成一个 JS 文件的加密后的一个指纹,然后在服务器下载下来的文件上面,也会对那个文件做一个指纹,然后再和这个标签上面的文件做指纹的比对。如果发现不一样,就会认为这个文件被篡改了,是被劫持的。
当然防劫持的目的达到了,但同时也带来了新的问题——白屏。因为浏览器认为资源不可信,就不会去执行 JS 了,不会执行这些 JS 就不会去做任何异步尝试,也就说 JS 最终还是被当作加载失败来处理了。
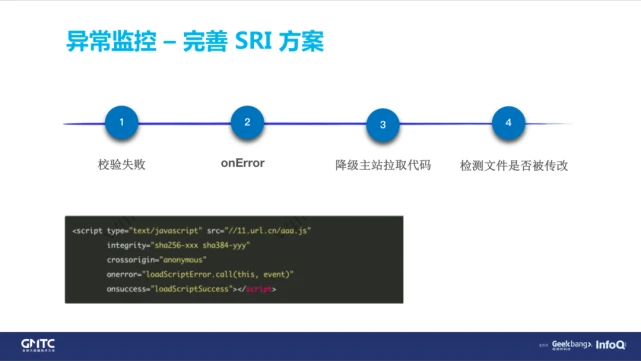
虽然看上去是浏览器运营商劫持导致的,归根结底,还是方案有缺陷。
当 SRI 失败的时候,还是会触发 Script Error 事件。所以我们要做一些补充的方案,如果 Script 触发 onError ,我们会向主栈拉取一次 JS 资源,不是 CDN 节点上的 JS,然后拉取主栈的 JS 的话,我们会取他前头部的几个字节以及尾部的字节,和我们现有的 CDN 上的资源做一个对比,全文对比太长了,我们做前后的这种字符检测就可以了。如果检查字符不一样,我们就直接使用主栈的资源进行加载,然后再走到上报的平台。
关于‘xxx’ is undefined 的总结:
后端接口的数据不可信,该做的判断一定不能少。
资源加载失败不一定是网络问题。
在引入一些其他的优化方案的时候,要考虑一下它的副作用。可能这个问题不是你导致的,但是别人的问题可能会导致你的问题!
接下来聊下 Script Error,这个问题也比较老生常谈了,大家应该都知道加个跨域头就可以解决。但其实往往加了跨域头,发现还是有大量的 Script Error。
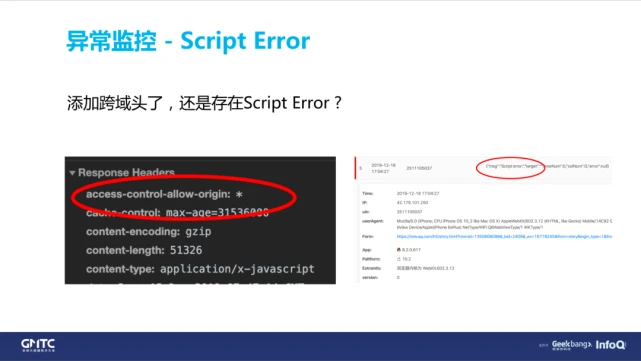
Script Error 原因

为什么还会存在 Script Error 呢?我们遇到的原因大致分为以下 3 类:
第 1, iOS 中跨域的异步脚本的报错信息在 window.onError 中是捕获不到的。
举个例子,在 a 域名的页面下引入了 b 域名的脚本,b 域名的脚本在执行 setTimeout 中的一段代码,出现了异常。window.onError 是无法获取到这个错误的。
目前针对这种情况的解决方法,只能对异步脚本中的代码手动地抛出错误进行捕获。
第 2,通过 native 代码执行的脚本报错,是无法被捕获的。
对于 Hybird 的 APP 中一些复杂的页面,客户端都会去调一些我们 JS 的代码,执行一些能力。客户端同学可能网上搜了一段代码,并不会告诉你这段代码有什么,然后本地跑执行没问题,所以他就直接加上去了。但比如说他回调你页面里面的一个接口,windows 怎么 xxx 执行一下。但其实可能你代码有什么问题,或者是他在你的代码声明之前就执行了,这个时候实际上也会有报错且没有 Script Error ,所以这种问题你就需要联合客户端这边,要对他们执行的这种 JS 代码做一些保护,常见的就是执行前,先对 JS 回调进行检查。

第 3,因为一些离线缓存实现的问题不太对,现在一些大的 App 里面,都有做这种离线缓存功能。理论上来说,把接口拦截掉,返回一个本地的资源,当然资源的 Header 是客户端来设置的,这个时候不会设置跨域头,也会报 Script Error 。为了解决这个问题,我们做了一个临时策略,把离线包里面所有的资源都换成主域的资源,解决历史版本中的问题,同时推动客户端添加缓存头。
防止 Script Error 总结
通过 patch 方法 。
客户端所有调用的 JS 方法需要做保护。
客户端也需要添加缓存头 。
简单总结一下,在现代各种端比较复杂的情况下,各种原因都可能导致问题。大家分析问题的时候,眼光要尽可能放长远。
6. 性能监控
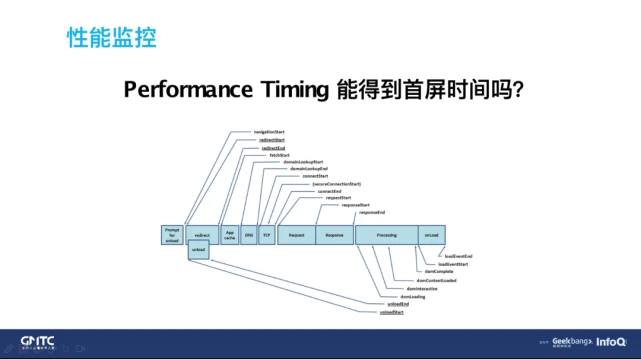
首先是前面提到的 Performance Timing,其实它已经不能反映出现在的一个首屏时间了。现在 Webview 的起始点:
第 1 是这种现代的 SPA 的框架,让 Performance Timing 失去意义了。
第 2 是一些复杂的加载方式,比如说腾讯的 Vas sonic 这种方式,其中最大的特点就是,在 WebView 打开的时候会并行的去请求 HTML,而不是等 WebView 加载好之后再去请求,这会节省很多时间。
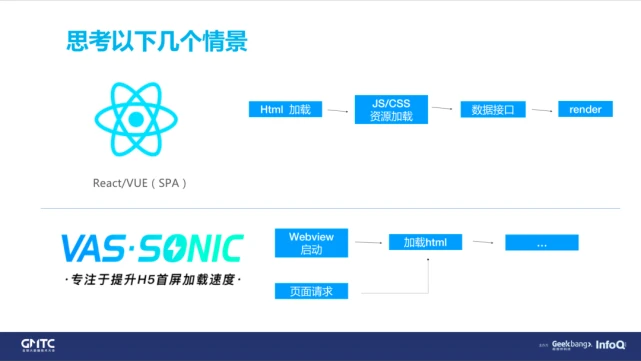

所以在统计性能监控的起始时间的时候,必须以 WebView 打开的时间作为起始点。如何统计到 WebView 的打开时间呢?
我们的做法是:和客户端约定,客户端在 url 上注入 ”_t“ 参数作为 WebView 的时间,否则就以 Performance Timing 启动的时间作为我们的起始时间点。
再说一下我们首屏计算,这个 API 我其实不太看好,它只是告诉我们绘制的第一帧,
但是不会反映出真正的时间。所以还要看后面标准会不会有新的变化。
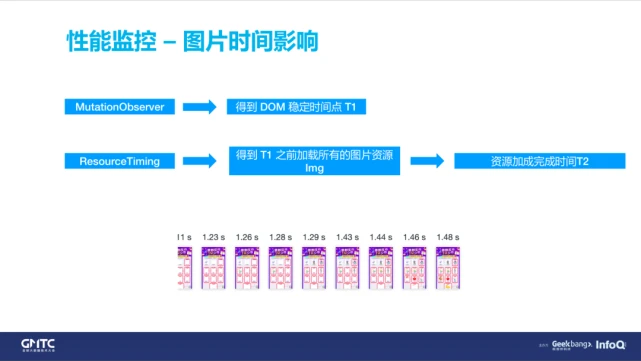
然后说一下我们是怎么计算首屏时间的。整个算法比较简单,通过 MutationObserver 去拿到 DOM 的变化,然后在 5 秒内到最后一个变化的稳定时间点,作为时间点 T1,然后再取 ResourseTiming 在 T1 时间内加载的所有的图片资源,然后取到图片资源加载完成的一个时间 T2,T2 就是我们作为首屏的一个时间点。
前端监控方案 Aegis 系统架构
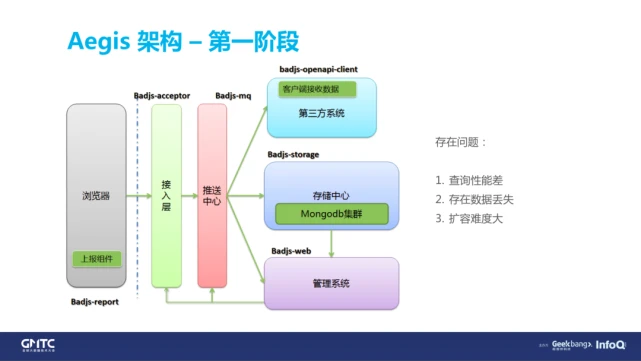
最后讲一下 Aegis 的架构,这个图为什么这么老?因为直接把 BadJS 的架构拿来了。我们第一版也很简单,就直接沿用了 BADJS 的架构,各种缺点在这里就不再赘述了。
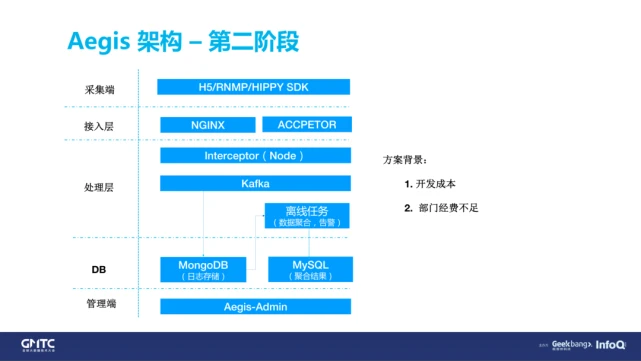
第二版架构图,当时也考虑了用一些 ELK 或者用一些实时计算平台,但为什么最后没有用,而是选择了一些偏前端的技术上的一些东西?原因很简单,因为穷。大家可以看到一些 ELK 在腾讯云上,64G 的一年要 5 万块钱,所以部门经费制约了我们去尝试新的技术。
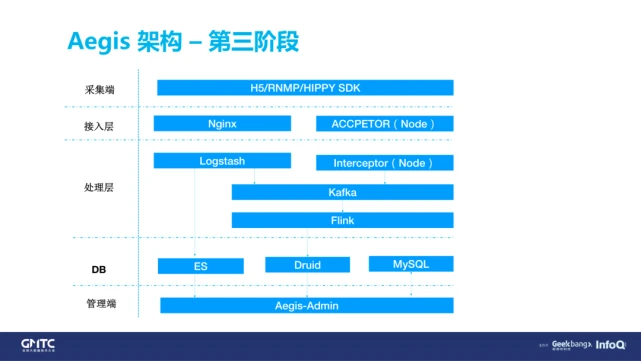
第三阶段我们就比较幸福了,因为去年腾讯开始号召开源协同,我们也很顺利地抱上了腾讯云的大腿,腾讯云给我们提供了一些很好的服务器端的支持,所以我们也引入了 Flink、Druid 这些实时计算的东西,来帮助我们提升 Aegis 的架构系统。
以上就是 NOW 直播在大前端时代下的监控体系建设,希望能给大家带来一些参考。
作者介绍
何方舟,现在是腾讯 NOW 直播的中台的前端负责人。曾任职于京东,2016 年加入腾讯,先后负责 NOW 直播 SDK,腾讯直播基础功能研发。前端监控开源项目 Aegis 项目负责人,对前端性能优化、前端工程化、Node.js 同构有丰富经验。
活动推荐
上一篇: 化工园区环境监控预警平台
下一篇: 吉林省财税信息中心会计考试监控平台



