
AI 音辨世界:艺术小白的我,靠这个AI模型,速识音乐流派选择音乐
音乐领域,借助于歌曲相关信息,模型可以根据歌曲的音频和歌词特征,将歌曲精准进行流派分类。本文讲解如何基于机器学习完成对音乐的识别分类。




只要给到足够的相关信息,AI模型可以迅速学习一个新的领域问题,并构建起很好的知识和预估系统。比如音乐领域,借助于歌曲相关信息,模型可以根据歌曲的音频和歌词特征将歌曲精准进行流派分类。在本篇内容中 ShowMeAI 就带大家一起来看看,如何基于机器学习完成对音乐的识别分类。
本篇内容使用到的数据集为 ,大家也可以通过 ShowMeAI 的百度网盘地址快速下载。
我们在本篇内容中将用到最常用的 boosting 集成工具库 LightGBM,并且将结合 optuna 工具库对其进行超参数调优,优化模型效果。




本篇文章包含以下内容板块:
- 数据概览和预处理
- EDA探索性数据分析
- 歌词特征&数据降维
- 建模和超参数优化
- 总结&经验
数据概览和预处理
本次使用的数据集包含超过 18000 首歌曲的信息,包括其音频特征信息(如活力度,播放速度或调性等),以及歌曲的歌词。
我们读取数据并做一个速览如下:
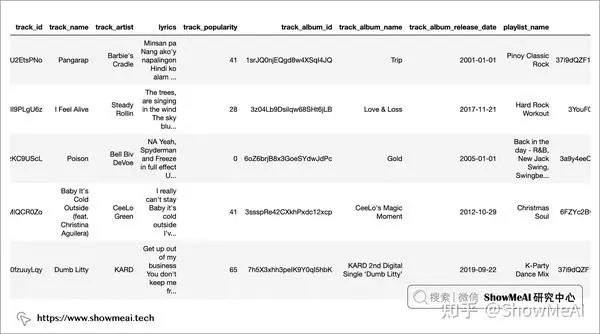
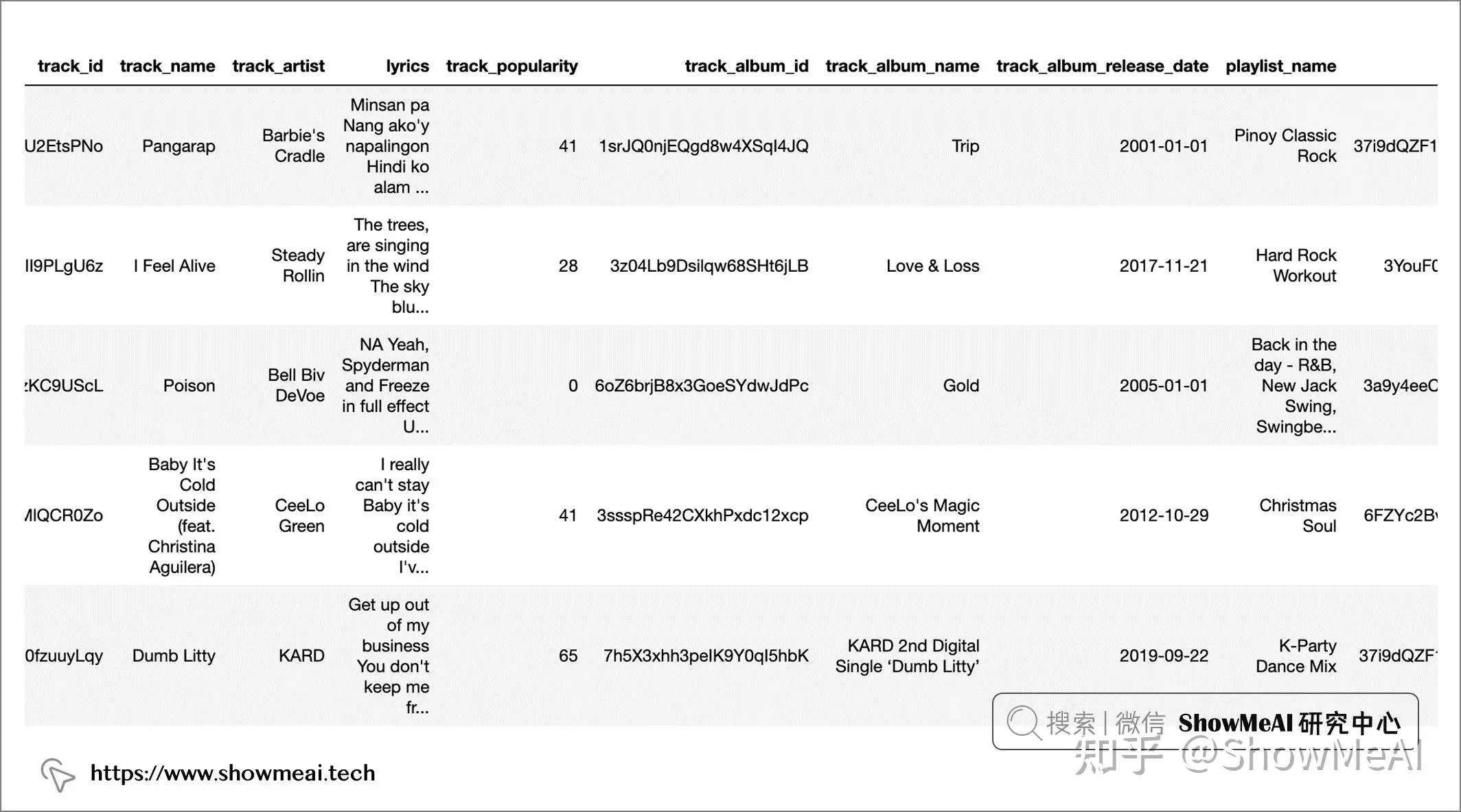
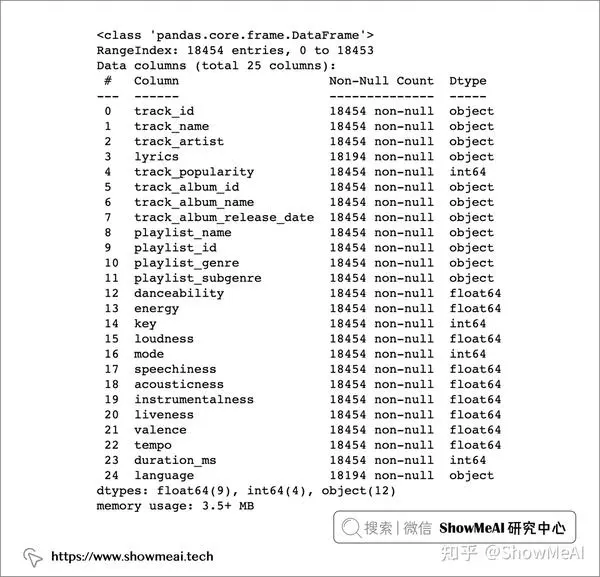
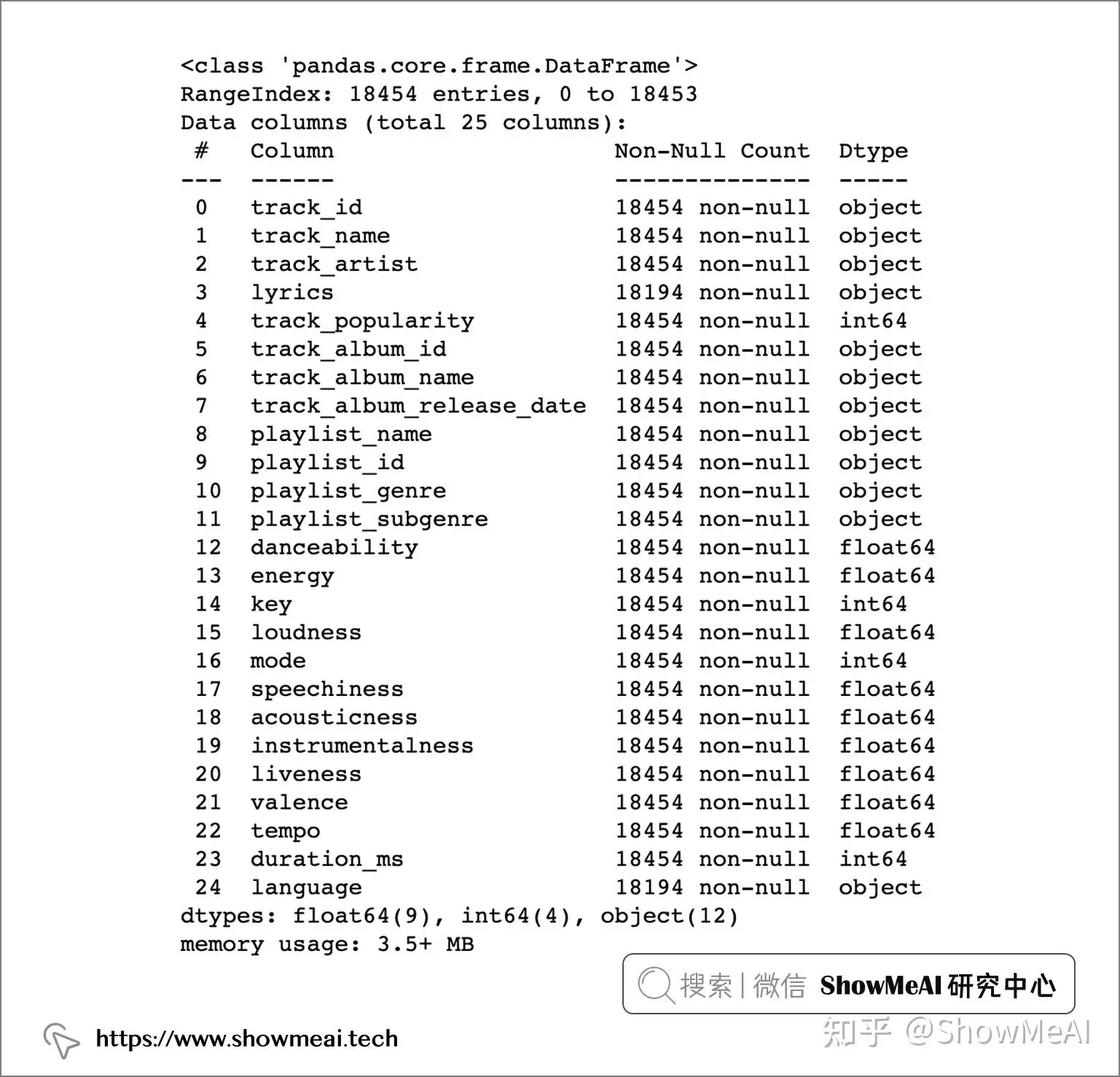
字段说明如下:
| 字段 | 含义 |
|---|---|
| track_id | 歌曲唯一ID |
| track_name | 歌曲名称 |
| track_artist | 歌手 |
| lyrics | 歌词 |
| track_popularity | 唱片热度 |
| track_album_id | 唱片的唯一ID |
| track_album_name | 唱片名字 |
| track_album_release_date | 唱片发行日期 |
| playlist_name | 歌单名称 |
| playlist_id | 歌单ID |
| playlist_genre | 歌单风格 |
| playlist_subgenre | 歌单子风格 |
| danceability | 舞蹈性描述的是根据音乐元素的组合,包括速度、节奏的稳定性、节拍的强度和整体的规律性,来衡量一首曲目是否适合跳舞。0.0的值是最不适合跳舞的,1.0是最适合跳舞的。 |
| energy | 能量是一个从0.0到1.0的度量,代表强度和活动的感知度。一般来说,有能量的曲目给人的感觉是快速、响亮。例如,死亡金属有很高的能量,而巴赫的前奏曲在该量表中得分较低。 |
| key | 音轨的估测总调。用标准的音阶符号将整数映射为音高。例如,0=C,1=C♯/D♭,2=D,以此类推。如果没有检测到音调,则数值为-1。 |
| loudness | 轨道的整体响度,单位是分贝(dB)。响度值是整个音轨的平均值,对于比较音轨的相对响度非常有用。 |
| mode | 模式表示音轨的调式(大调或小调),即其旋律内容所来自的音阶类型。大调用1表示,小调用0表示。 |
| speechiness | 言语性检测音轨中是否有口语。录音越是完全类似于语音(如脱口秀、说唱、诗歌),属性值就越接近1.0。 |
| acousticness | 衡量音轨是否为声学的信心指数,从0.0到1.0。1.0表示该曲目为原声的高置信度。 |
| instrumentalness | 预测一个音轨是否包含人声。越接近1.0该曲目就越有可能不包含人声内容。 |
| liveness | 检测录音中是否有听众存在。越接近现场演出数值越大。 |
| valence | 0.0到1.0,描述了一个音轨所传达的音乐积极性,接近1的曲目听起来更积极(如快乐、欢快、兴奋),而接近0的曲目听起来更消极(如悲伤、压抑、愤怒)。 |
| tempo | 轨道的整体估计速度,单位是每分钟节拍(BPM)。 |
| duration_ms | 歌曲的持续时间(毫秒) |
| language | 歌词的语言语种 |
原始的数据有点杂乱,我们先进行过滤和数据清洗。
主要的数据预处理在上述代码的注释里大家可以看到,核心步骤概述如下:
- 过滤数据以仅包含英语歌曲并删除“拉丁”类型的歌曲(因为这些歌曲几乎完全是西班牙语,所以会产生严重的类不平衡)。
- 通过将歌词设为小写、删除标点符号和停用词来整理歌词。计算每个剩余单词在歌曲歌词中出现的次数,然后过滤掉所有歌曲中出现频率最低的单词(混乱的数据/噪音)。
- 清理与排序。
EDA探索性数据分析
和过往所有的项目一样,我们也需要先对数据做一些分析和更进一步的理解,也就是EDA探索性数据分析过程。
首先我们检查一下我们的标签(流派)的类分布和平衡。
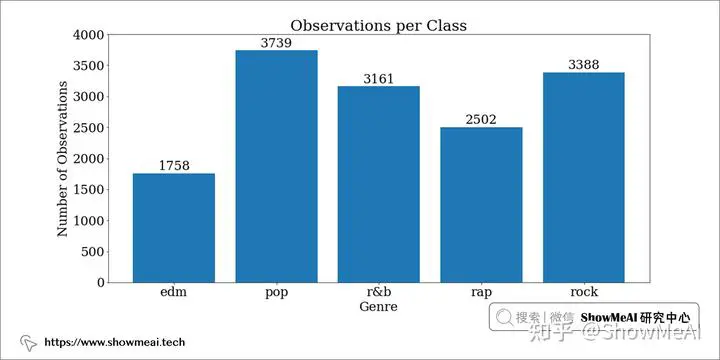
存在轻微的类别不平衡,那后续我们在交叉验证和训练测试拆分时候注意数据分层(保持比例分布) 即可。
歌词特征&数据降维
我们的机器学习算法在处理高维数据的时候,可能会有一些性能问题,有时候我们会对数据进行降维处理。
降维的本质是将高维数据投影到低维子空间中,同时尽可能多地保留数据中的信息。关于降维大家可以查看 ShowMeAI 的算法原理讲解文章
我们探索一下降维算法(PCA 和 t-SNE)在我们的歌词数据上降维是否合适,并做一点调整。
PCA主成分分析
PCA是最常用的降维算法之一,我们借助这个算法可以对数据进行降维,并且看到它保留大概多少的原始信息量。例如,在我们当前场景中,如果将歌词减少到400 维,我们仍然保留了歌词中60% 的信息(方差) ;如果降维到800维,则可以覆盖 80% 的原始信息(方差)。歌词本身是很稀疏的,我们对其降维也能让模型更好地建模。
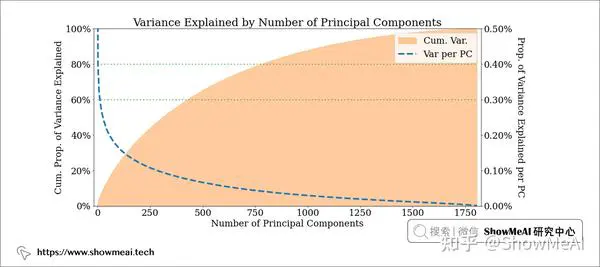
t-SNE可视化
我们还可以更进一步,可视化数据在一系列降维过程中的可分离性。t-SNE算法是一个非常有效的非线性降维可视化方法,借助于它,我们可以把数据绘制在二维平面观察其分散程度。下面的t-SNE可视化展示了当我们使用所有1806个特征或将其减少为 1000、500、100 个主成分时,如果将歌词数据投影到二维空间中会是什么样子。
代码如下:
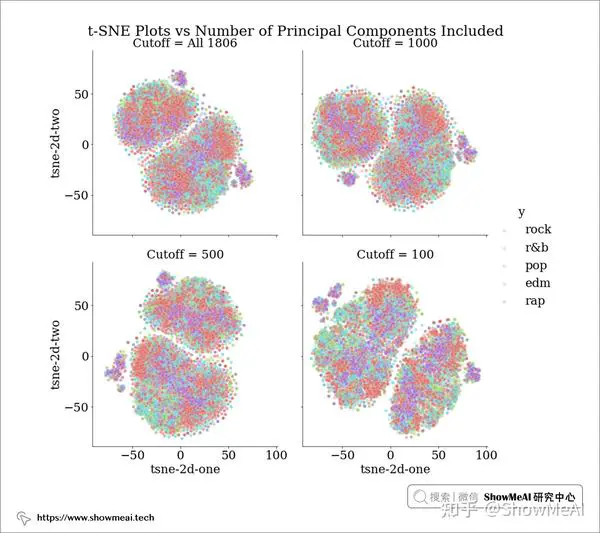
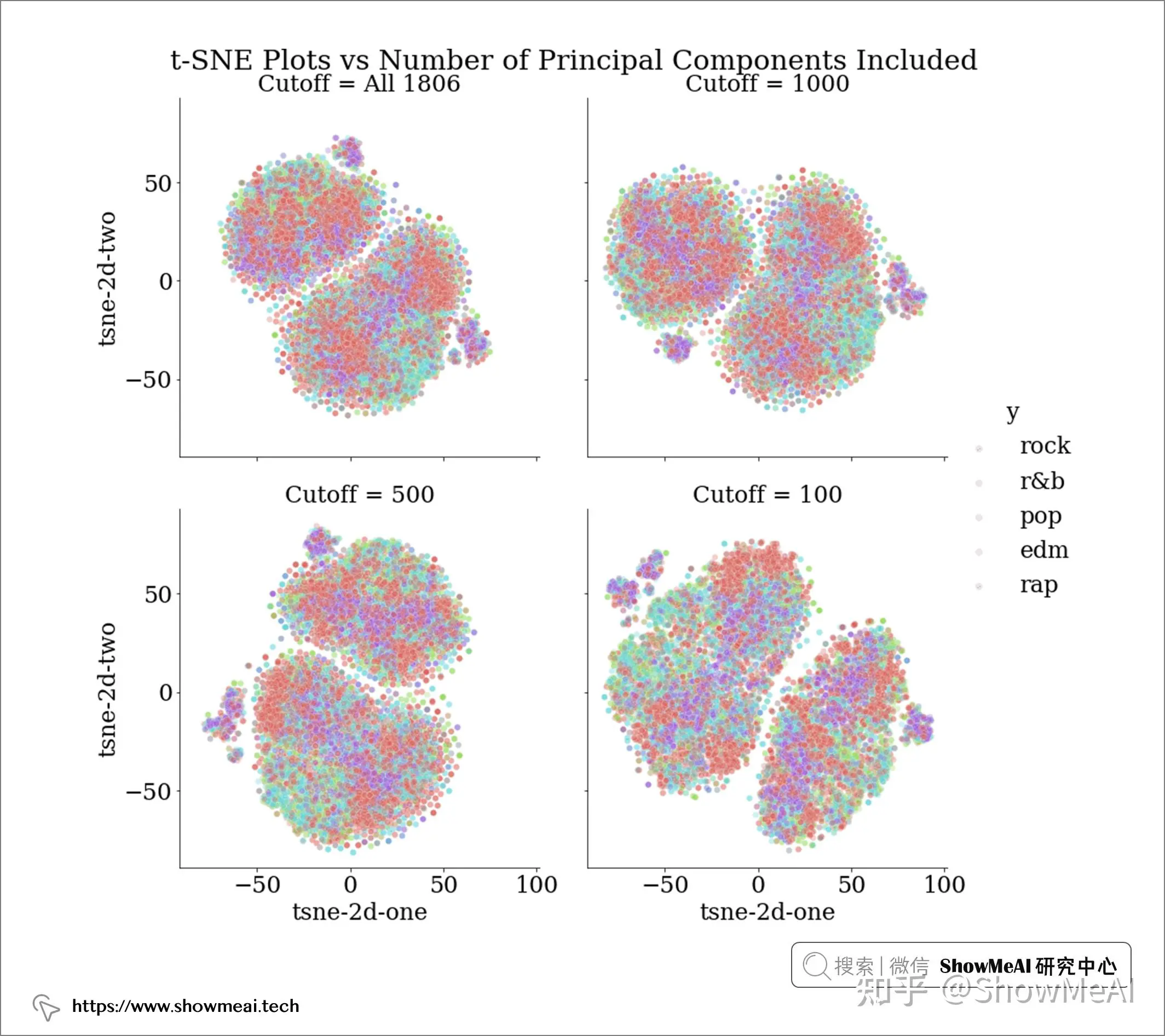
理想情况下,我们希望看到的是,在降维到某些主成分数量(例如 cutoff = 1000)时,流派变得更加可分离。
然而,上述 t-SNE 图的结果显示,PCA 这一步不同数量的主成分并没有哪个会让数据标签更可分离。
自编码器降维
实际上我们有不同的方式可以完成数据降维任务,在下面的代码中,我们提供了 PCA、截断 SVD 和 Keras 自编码器三种方式作为候选,调整配置即可进行选择。
autoencodecustom_functions.py上述过程之后我们已经完成对数据的标准化、编码转换和降维,接下来我们使用它进行建模。
建模和超参数优化
构建模型
在实际建模之前,我们要先选定一个评估指标来评估我们模型的性能,也方便指导进一步的优化。由于我们数据最终的标签『流派/类别』略有不平衡,宏观 F1 分数(macro f1-score) 可能是一个不错的选择,因为它平等地评估了类别的贡献。我们在下面对这个评估准则进行定义,也敲定 LightGBM 模型的部分超参数。
LightGBM 带有大量可调超参数,这些超参数对于最终效果影响很大。
关于 LightGBM 的超参数细节详细讲解,欢迎大家查阅 ShowMeAI 的文章:
param超参数优化
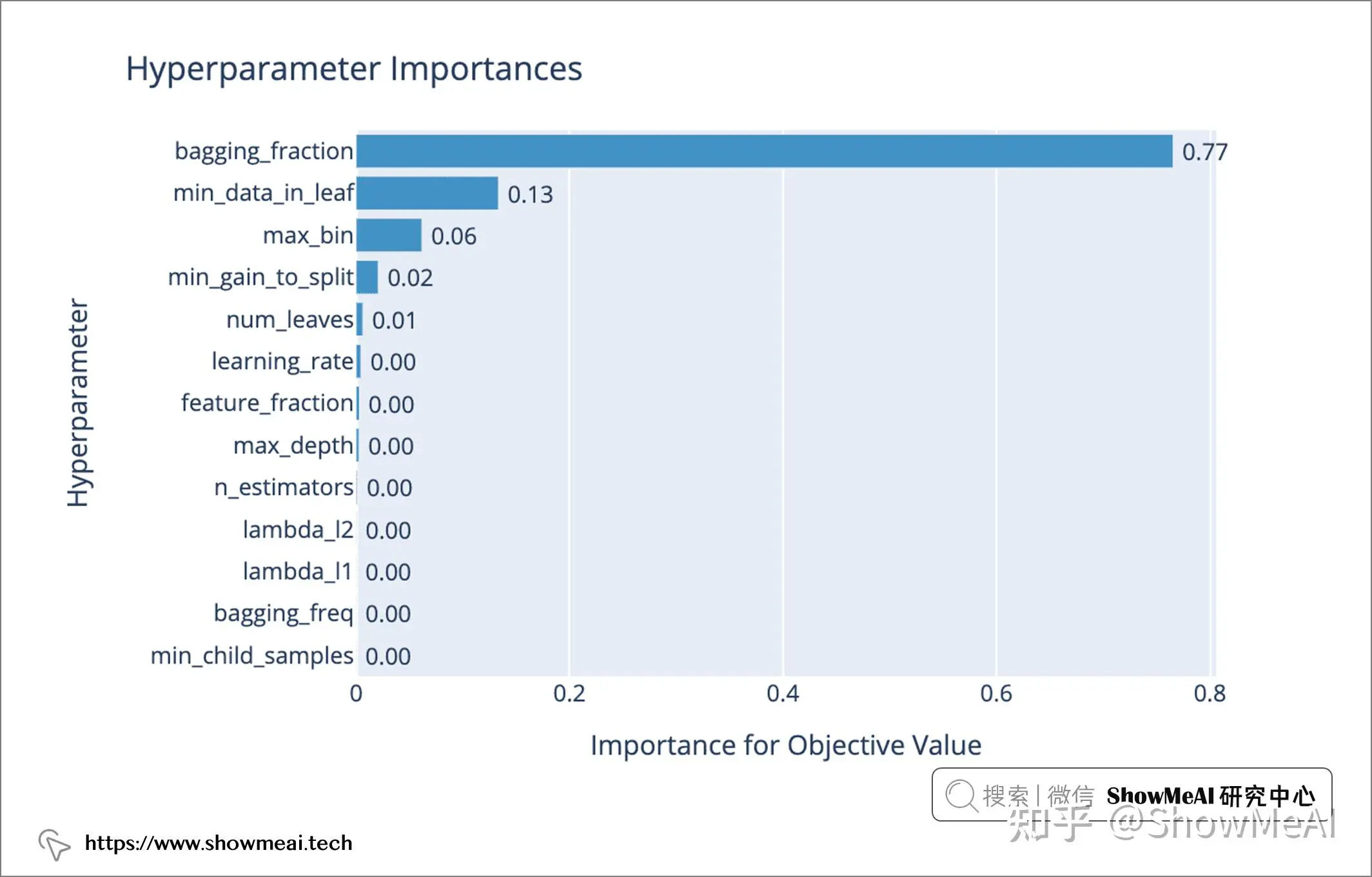
我们在上面定义完了目标函数,现在可以使用 Optuna 来调优模型的超参数了。
plot_param_importances(study)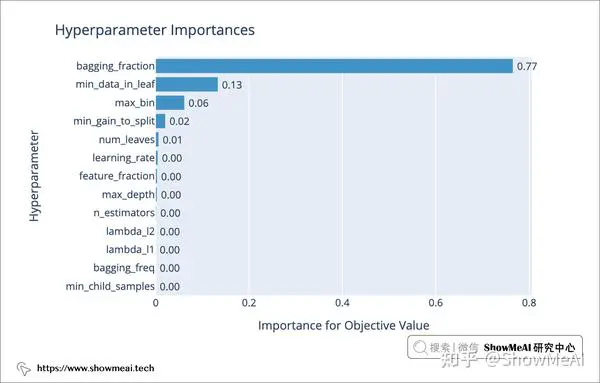
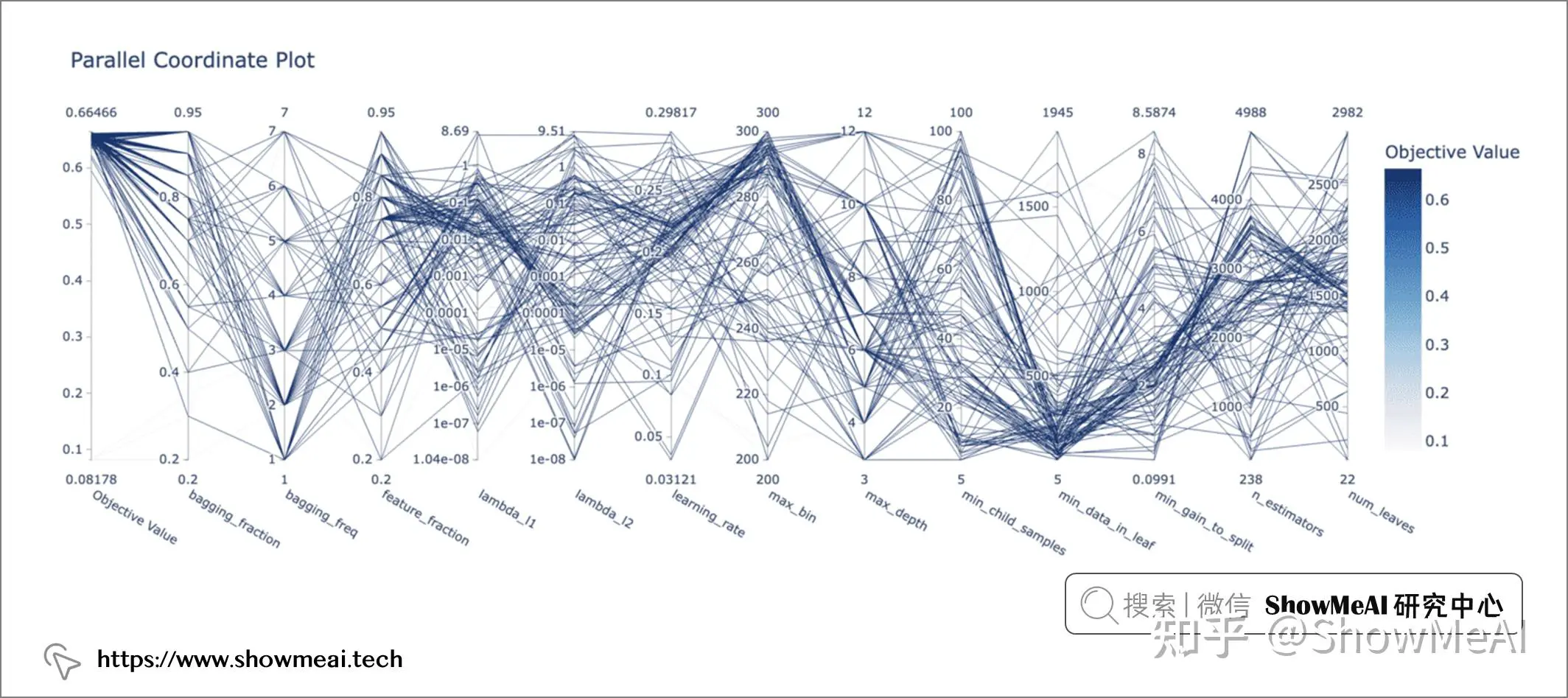
plot_parallel_coordinate(study)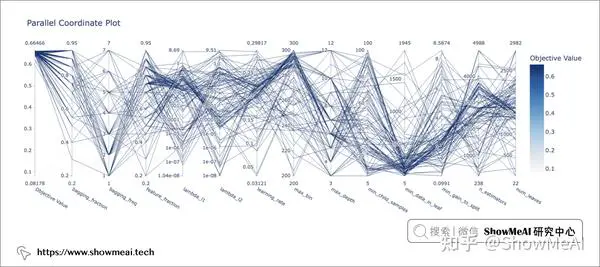
plot_optimization_history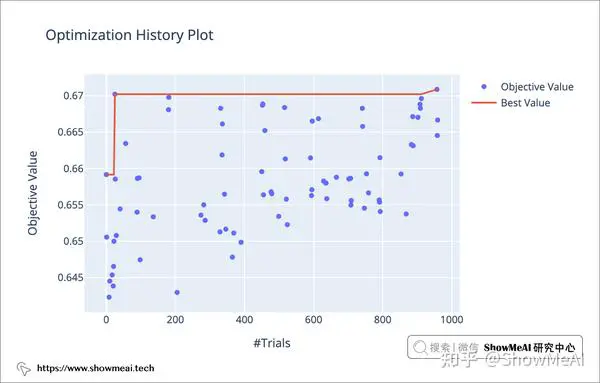
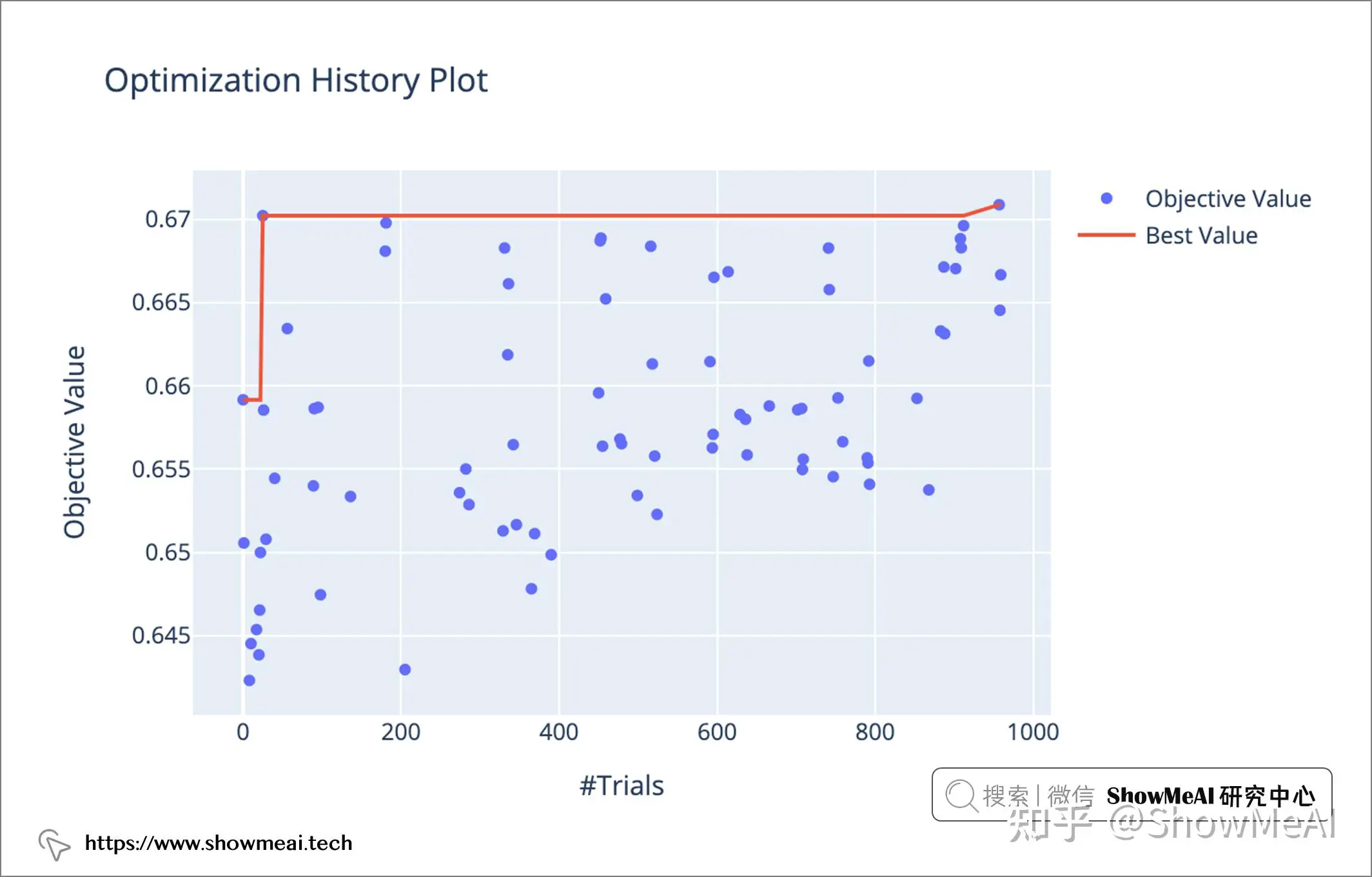
在Optuna完成调优之后:
study.best_paramsparamsparams = {**fixed_params, **study.best_params}最终评估
通过上述过程我们就获得了最终模型,让我们来评估一下吧!
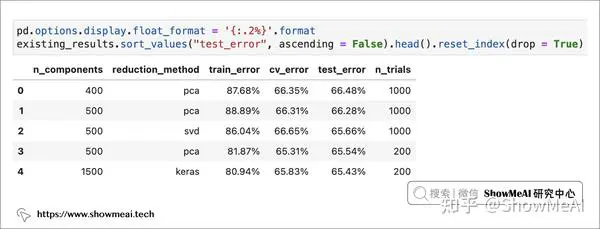
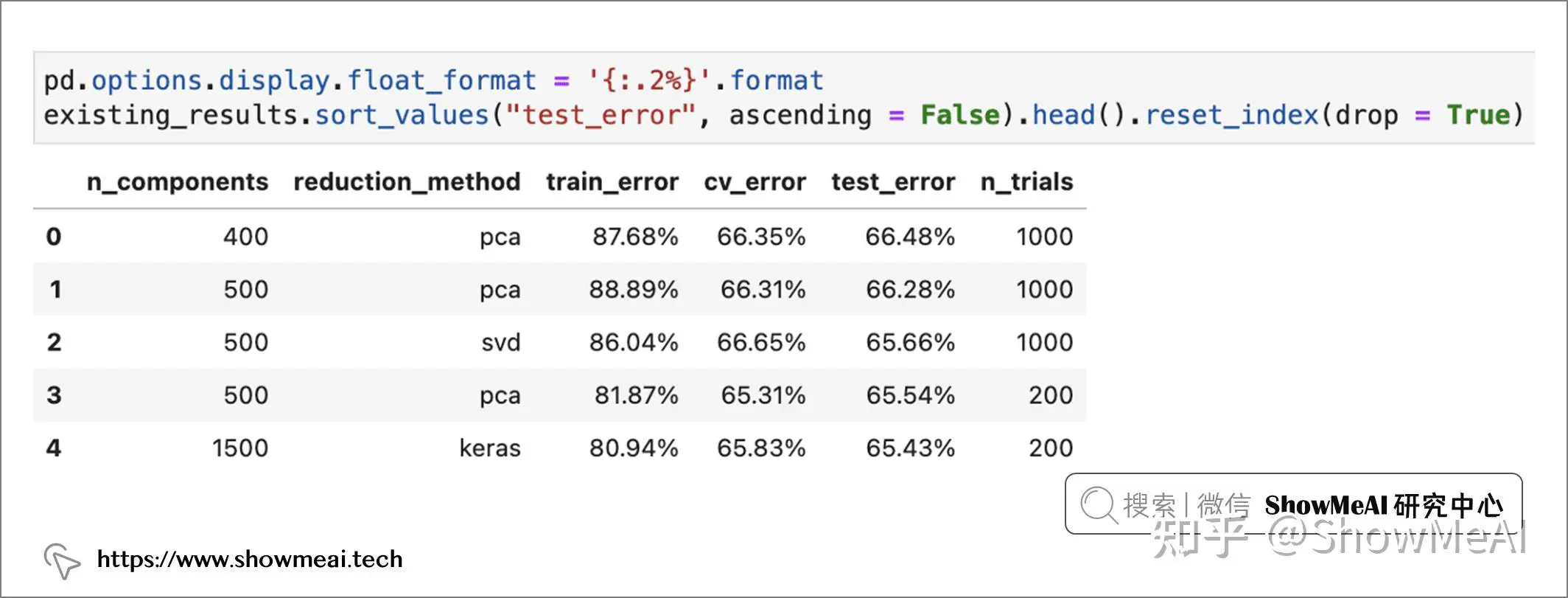
我们可以实验和比较不同的降维方法、降维维度,再调参查看模型效果。如下图所示,在我们当前的尝试中,PCA降维到 400 维产出最好的模型 ——macro f1-score 为66.48%。
总结
在本篇内容中, ShowMeAI 展示了基于歌曲信息与文本对其进行『流派』分类的过程,包含对文本数据的处理、特征工程、模型建模和超参数优化等。大家可以把整个pipeline作为一个模板来应用在其他任务当中。
参考资料





